Station X w3up Opportunities
TL;DR
This document looks into how Station could take on certain roles in the w3up infrastructure. It analyses each one based on certain criteria such as:
- costs
- Station node requirements
- orchestration requirements
- Verifiability/provability
Store/Add Flow
When a w3up client wants to upload a CAR file into w3up, they create a UCAN with the capability store/add and ask the w3up server for a pre-signed upload URL. The W3up server responds with a pre-signed URL and the client is able to upload their CAR to a remote CAR store such as S3 or R2. In upcoming steps of the w3up protocol, S3 will be asked to serve the CAR file to other nodes who are writing aggregated content onto Filecoin.
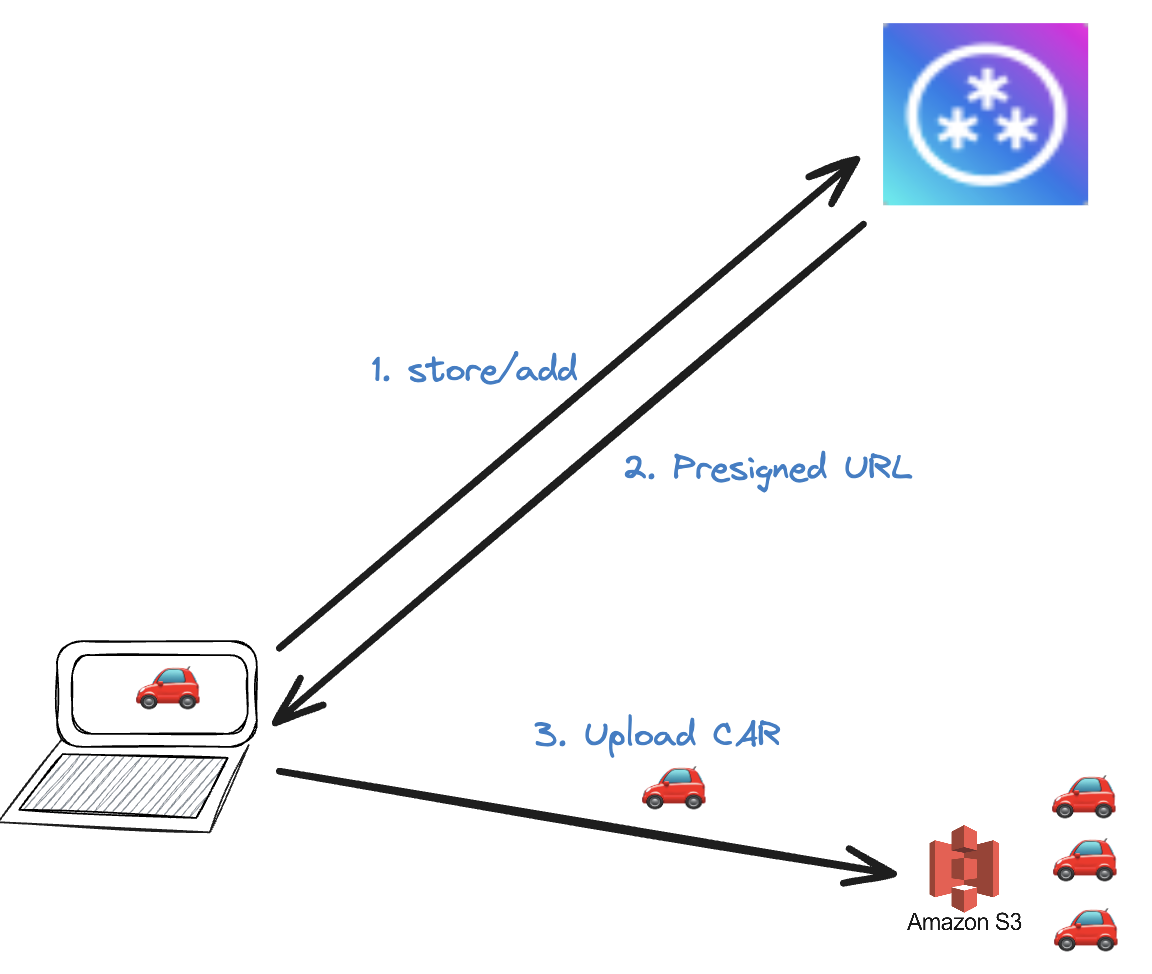
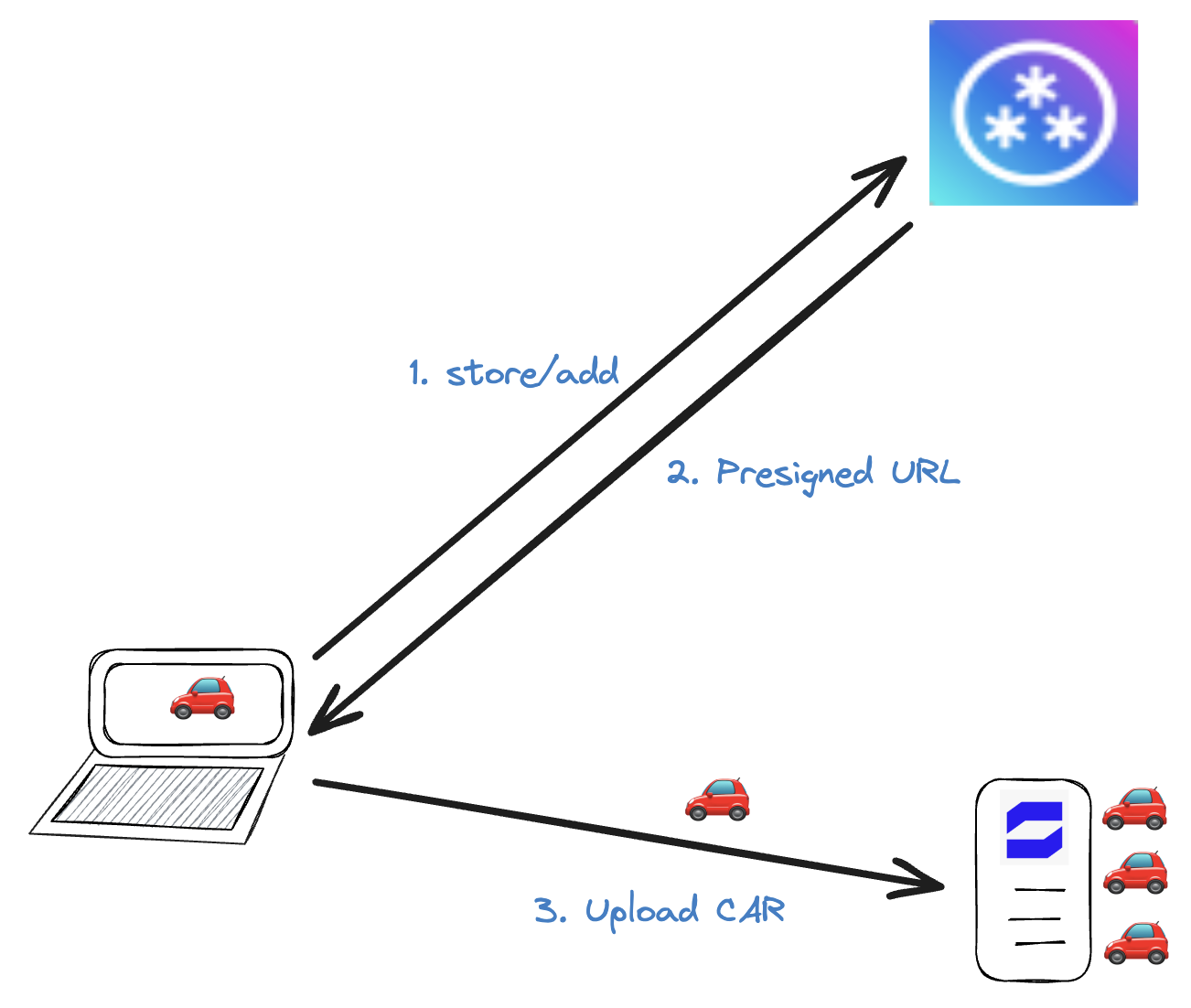
Opportunity: Station nodes as remote CAR Store
Instead of uploading the CAR to S3 or R2 or another big cloud provider, the client could instead upload it to a Station Node! In upcoming steps of the w3up protocol, this Station node will be asked to serve the CAR file to other nodes who are writing aggregated content onto Filecoin.
Current W3up Costs
- S3 (and/or R2) upload ingress
- S3 (and/or R2) egress
- S3 (and/or R2) storage space
Station Requirements
- Station server nodes only
- Symmetric and high bandwidth (10 gig line?)
- Fixed IP
- Reliable constant uptime
- Storage capacity (32GB per sector)
Orchestration
- How do we orchestrate which Station server node stores which CAR files?
- Consistent hashing ring?
- Geo-sensitive?
- Back-ups?
- How do we index which Station node holds which CAR files?
Verifiability/Provability
- How do we add verifiability and provability to this module?
- Station node creates a UCAN receipt when it has received the file
- Station node waits for Filecoin storage deal to be made which provides a receipt that the CAR has been stored in FIlecoin
- Station submits both the above to the measurement service in order to get rewarded
- If a Station is consistently failing to store CARs they can be removed from the network. We may require staking or node reputation here to ensure we don’t get anon Stations sabotaging the system.
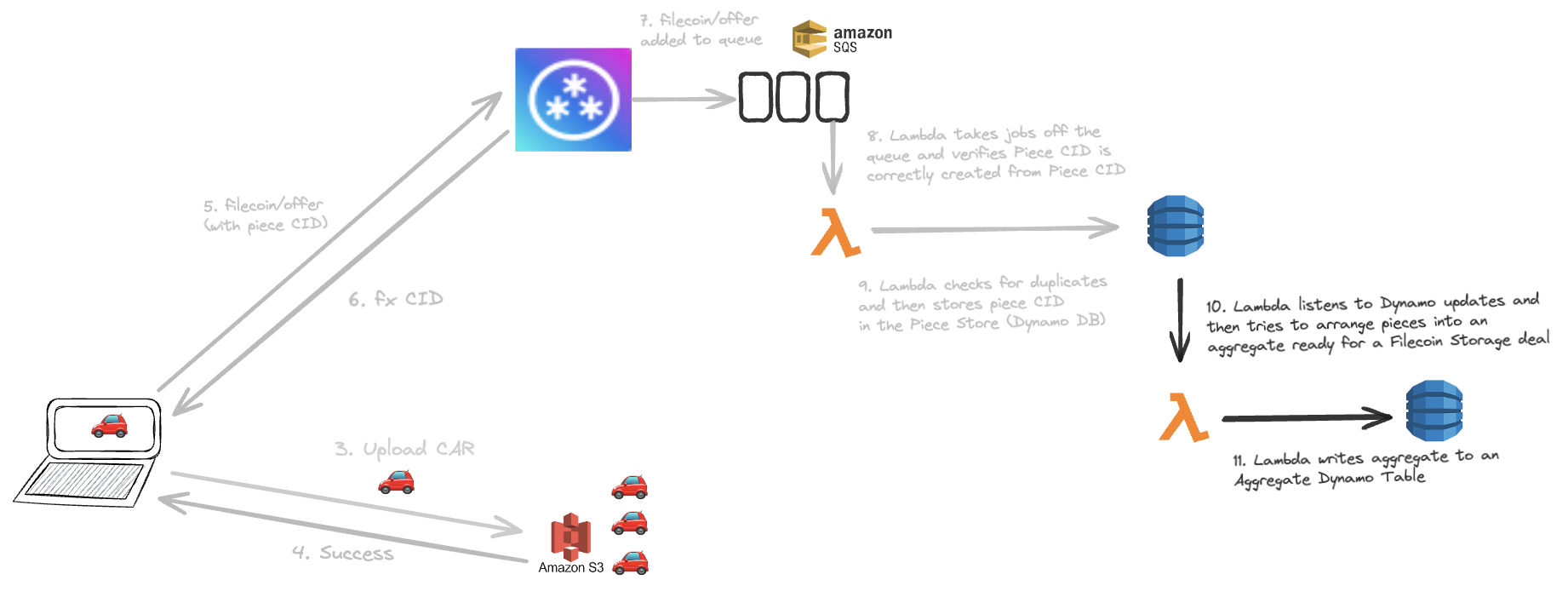
Filecoin/Offer Flow
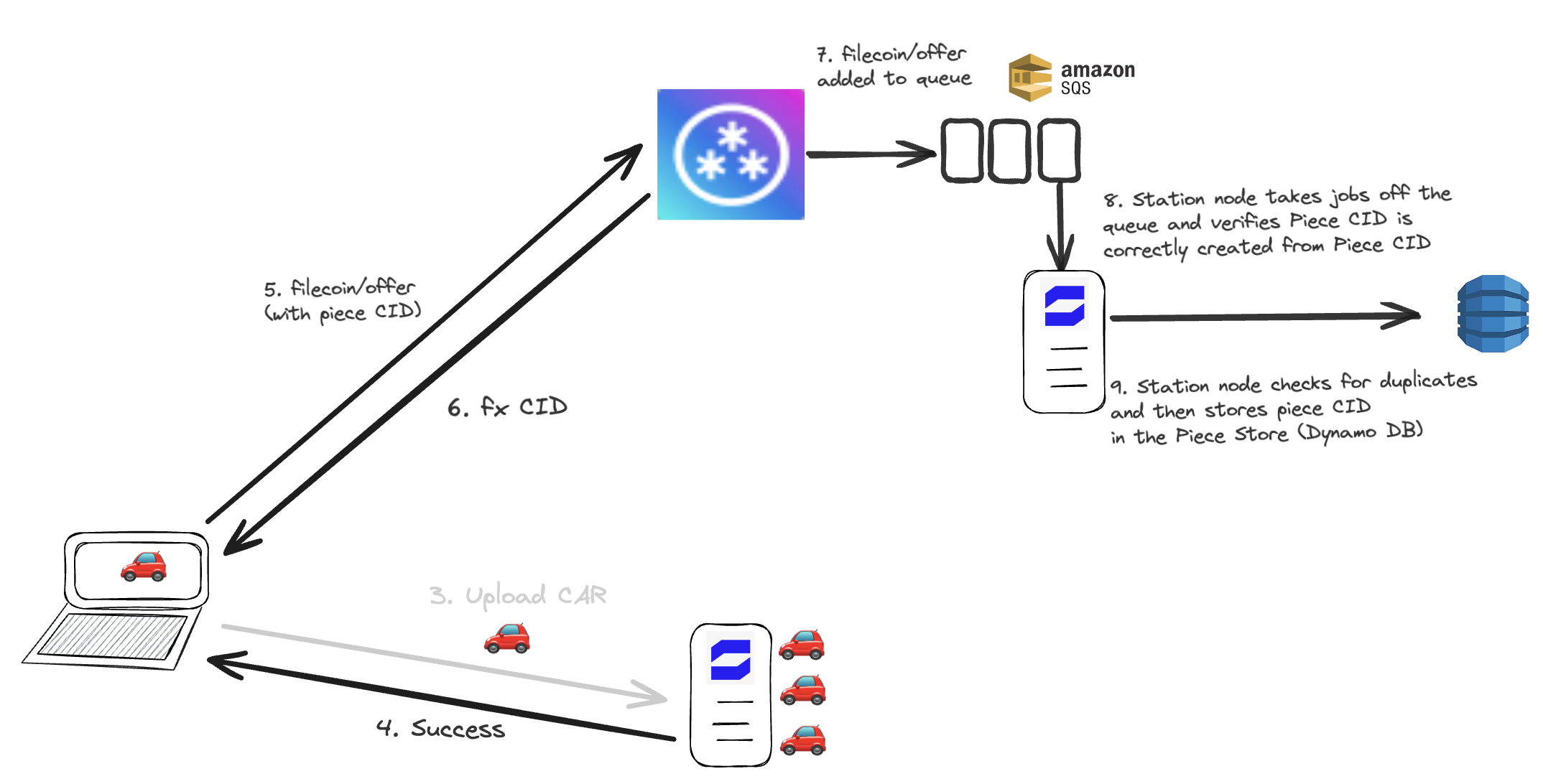
When the end user has learnt that their upload was successful, they create a Piece CID for the CAR on the device and then they send a request with a UCAN with filecoin/offer capability into w3up infra. The request payload includes the CAR CID & the newly created Piece CID. W3up adds this request to a queue. A Lambda is triggered by this queue and consumes a firehose of piece CIDs with their corresponding sizes.. It verifies that the Piece CID is correctly created from the CAR CID, and that the piece CID is not already stored in w3up infra to avoid duplication.
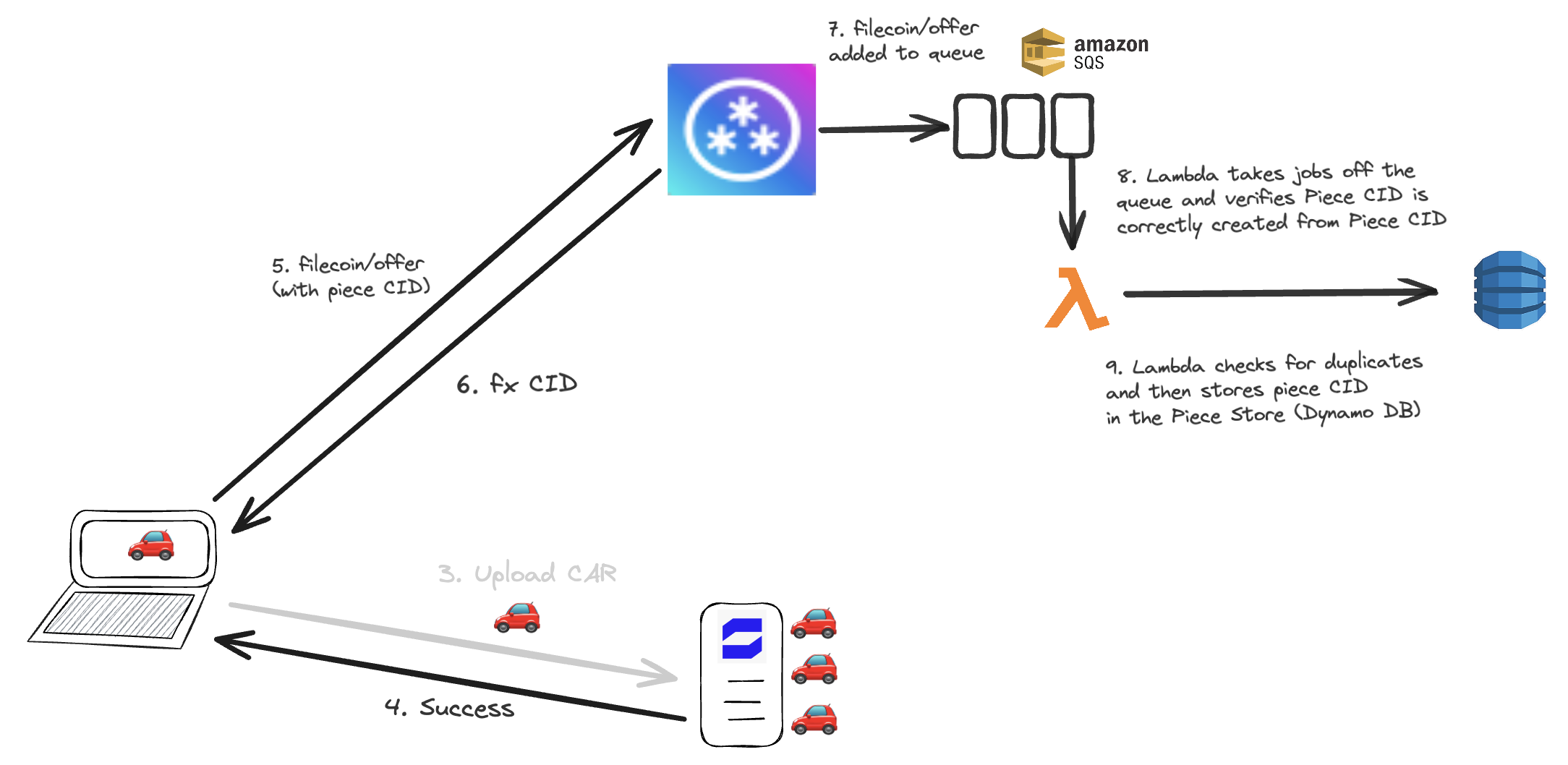
Opportunity: Station module to verify Piece CID and check for duplicates
Instead of Lambda doing this job, Station nodes can do it instead. Station nodes can listen to this firehose of Piece CIDs with their corresponding sizes and verify that the piece CID was correctly created.
Current W3up costs
- Lambda invocations (quite cheap?)
Station Requirement
- Reliable constant uptime
- Station server or Station desktop
- Doesn’t require high bandwidth
- Doesn’t require storage space
Orchestration
- How do we orchestrate which Station server node runs each invocation? We don’t want it just to be one operator.
- Geo-sensitive?
- Multiple Station perform the task and compare results? c.f. Bacalhau
Verifiability/Provability
- The Piece CID verification is itself a deterministic verification and the result is a yes or no. Stations might report the wrong answer if there are reasons to do so, but their response can be compared to other responses or rerun. If a Station is consistently giving the wrong answer they can be removed from the network. We may require staking or node reputation here to ensure we don’t get anon Stations sabotaging the system.
Piece/Offer Flow
When new pieces are added to Dynamo DB, Lambdas listen out to this firehose of events and then try to construct an optimised aggregation of those pieces that packs efficiently into a Filecoin Sector. We call this the sector packing problem.
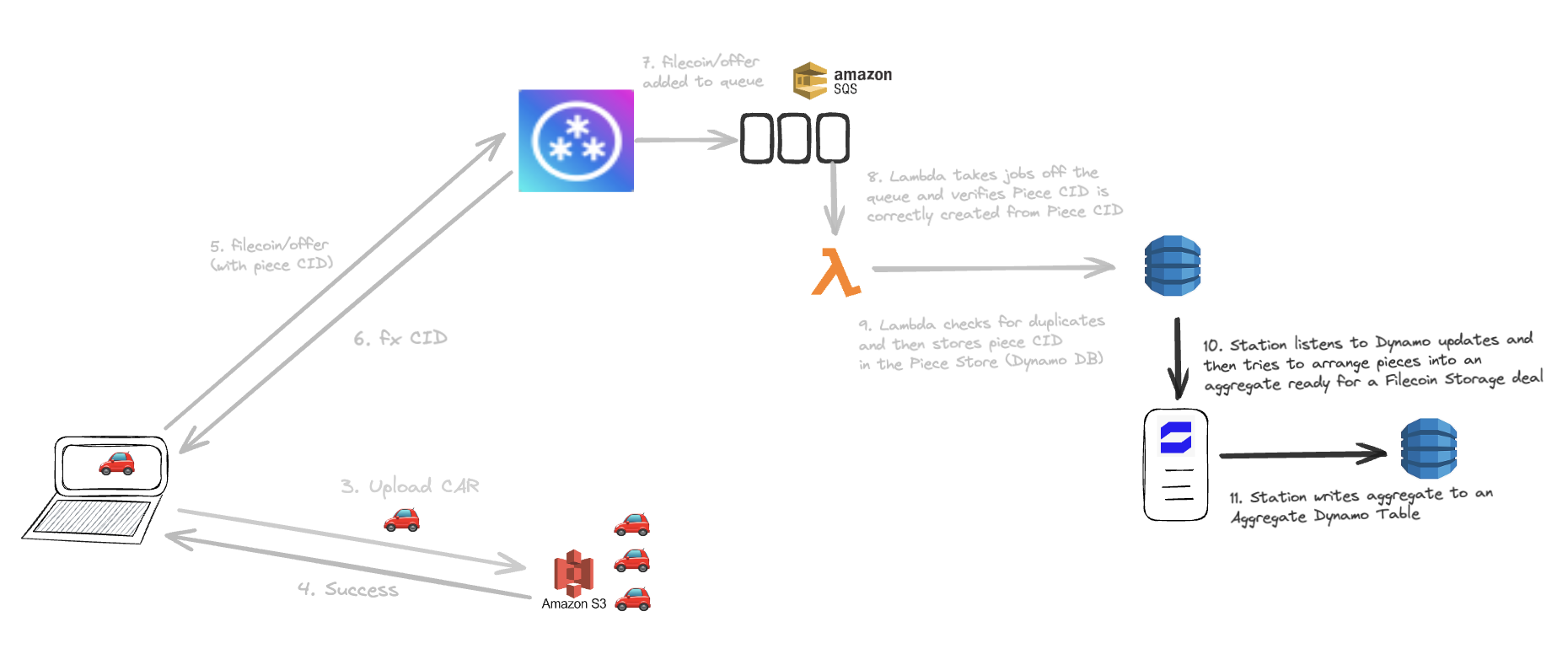
Opportunity: Station module constructs aggregate (packing problem)
Station replaces Lambda in performing this packing problem. Many Stations can listen to this firehose of events and compete to create the best pack of pieces and get chosen to be the packing solution for the on chain deal.
Code
Current W3up costs
- lambda invocations
- Dynamo DB table of aggregates
Station Requirement
- Reliable constant uptime?
- Station server or desktop
- Doesn’t require high bandwidth
- Doesn’t require storage space
- Might require some memory?
Orchestration
- How do we orchestrate which Station server node runs each invocation? We don’t want it just to be one operator.
- Geo-sensitive?
- Multiple Station perform the task and compare results? c.f. Bacalhau
Verifiability/Provability
- Once an aggregate has been turned into a sector on Filecoin then we can create end to end verifiability that the work done by the lambda was included in an on chain deal.
- If a Station submits trivial and useless aggregations that do not optimise, we will need a way to choose the most optimal pack and only reward the node that has achieved this. Station can compete to create the best packing of pieces so that their pack gets chosen to be in the on chain deal.
Deployment & Orchestration Layer
For each of these options, the w3up team would like to be able to update and deploy their worker code to the Station network just like one is able to deploy updated code to Lambdas.
The w3up use https://sst.dev for their deployment which offers a typescript interface for managing deployments.
Imagine if builders could deploy Station modules as simply as:
new StationModule({
name: "packer",
authenticator: "UCAN",
path: "modules/packer.module",
}
})Questions
- Should Station deploy all modules to all Stations? This would mean we would need each Station to have an orchestration layer to pick the function to be executed, fetch input arguments, execute the function, publish function’s output
- Should all station keep each module running continually or can they spin up on invocation like Cloudflare workers or lambdas?
- RUM use cases like Spark benefit from all Stations running jobs. The above use cases require only one Station to run each job, perhaps a few if we want redundancy or comparisons for verification. How should we choose which nodes get to run the jobs?
- Can we use Bacalhau as the basis for this orchestration?